Juan Domingo Farnós
Las máquinas (AI) las TIC, la internet… proporcionan información más rápido de lo que nadie podría haber imaginado, pero el aprendizaje es dar sentido a la información y el descubrimiento de su significado, el verdadero objetivo de la educación, y con las máquinas aun no lo hemos conseguido, aunque algunos estemos en ello..
- Velocidad de acceso a la información: Con la proliferación de la tecnología de la información y la comunicación (TIC), así como el desarrollo de la inteligencia artificial (IA), ahora podemos acceder a grandes cantidades de información de manera más rápida y eficiente de lo que hubiéramos imaginado hace unas décadas. La internet ha transformado la forma en que accedemos y compartimos conocimiento.
- Aprendizaje vs. dar sentido a la información: El aprendizaje no se limita a la acumulación de datos o hechos. Implica el proceso de comprensión, análisis y contextualización de la información para construir un conocimiento significativo. Es más que simplemente almacenar datos; se trata de entender su relevancia y cómo se relaciona con otros conceptos.
- Descubrimiento de significado: Este es el corazón del proceso educativo. Se refiere a la capacidad de tomar la información y convertirla en conocimiento que tiene sentido y relevancia en un contexto determinado. Implica la capacidad de conectar conceptos, extraer conclusiones, resolver problemas y aplicar el conocimiento de manera efectiva.
- El verdadero objetivo de la educación: Históricamente, la educación ha tenido como objetivo principal preparar a las personas para enfrentar los desafíos de la vida, tanto a nivel personal como en la sociedad. Esto incluye no solo adquirir conocimientos y habilidades, sino también desarrollar habilidades de pensamiento crítico, resolución de problemas y creatividad.
- Desafíos con la tecnología y la IA: Aunque las máquinas y la inteligencia artificial pueden ayudar en la recopilación y organización de información, aún enfrentan desafíos en el ámbito de dar sentido y significado a esta información. La comprensión contextual, la empatía, la creatividad y el juicio ético son aspectos que las máquinas aún no pueden replicar completamente.
- Algunos están trabajando en ello: Es cierto que hay avances en el campo de la inteligencia artificial y la educación. Hay investigadores y educadores que están explorando formas de utilizar la tecnología para mejorar la educación, como sistemas de tutoría inteligente, plataformas de aprendizaje adaptativo y herramientas de análisis de datos educativos.
Aunque la tecnología ha transformado la forma en que accedemos a la información, el verdadero desafío en educación sigue siendo ayudar a los estudiantes a dar sentido y significado a esta información. La educación efectiva sigue dependiendo de la capacidad de los seres humanos para comprender, contextualizar y aplicar el conocimiento de manera significativa en sus vidas.
Aunque la IA se ha utilizado en una amplia gama de aplicaciones, como la atención médica, la robótica, el comercio electrónico, las finanzas, el marketing digital, la fabricación y la gestión de la salud, todavía hay limitaciones en lo que las máquinas pueden hacer. La interpretación y comprensión de la información es una tarea que aún requiere la inteligencia humana.
Estamos próximos a la posibilidad de utilizar agentes que comprenden contextos, que sean capaces de hacer “coherente” el sentido de los flujos de datos variados para buscar información, descubrir y proporcionar el contenido necesario para cada uno en determinados aprendizajes.
Una cosa que me parece fascinante es la idea de que se podrá crear un “perfil de aprendizaje”, una identidad que es esencialmente un paquete digital de nuestras preferencias de aprendizaje y los contenidos del aprendizaje del pasado, que se podrá acceder por las máquina (PERSONALIZED LEARNING + MACHINE LEARNING. by Juan Domingo Farnos)
Esto permitirá que la “máquina” en realidad adapte sus interfaces de usuario, el contenido de aprendizaje y la experiencia en sí misma, y presentar información de una manera que se adapte a las preferencias de los humanos….eso sin duda nos lleva a la VERDADERA SOCIEDAD INTELIGENTE.
También nos puede llevar fuera de las “aulas”, Yan Lecun, director de investigación de IA, explica que el aprendizaje no supervisado (máquinas de enseñanza para aprender por sí mismos sin tener que decir explícitamente si todo lo que hacen es correcto o incorrecto) es la clave de la IA “verdadera”.
“Utilizamos un software que permita a los estudiantes a aprender según su plantemiento personalizado permitirá a los profesores hacer frente a las clases más grandes de manera efectiva, ya que el acompañamiento será as u vez más moderado, debido al autoaprendizje que como consecuencia se produce.
https://es.linkedin.com/…/software-para-un-aprendizaje-pers… SOFTWARE PARA UN APRENDIZAJE PERSONALIZADO! By Juan Domingo Farnos
Entramos en una época de fronteras porosas entre la inteligencia humana y la inteligencia artificial (con razón llamamos “inteligencia artificial”). Si solicitamos algo en línea, como comprar, aprender, un billete de avion…es posible que tengamos que demostrar, que no somos un BOT, una máquina. Y, cuando se trata del desafío que enfrenta la educación:
— la forma de proporcionar una educación de calidad para un gran número de estudiantes a un costo reducido
— la tentación de cruzar la frontera hombre-máquina y dejar que las máquinas (es decir, algoritmos) hagan el trabajo pesado es casi irresistible, es más, ya no es una tentación, realmente es una necesidad.
Las máquinas, las TIC, la internet… proporcionan información más rápido de lo que nadie podría haber imaginado, pero el aprendizaje es dar sentido a la información y el descubrimiento de su significado, el verdadero objetivo de la educación, y con las máquinas aun no lo hemos conseguido, aunque algunos estemos en ello
La máquina, en las tecnologías de aprendizaje adaptativo, se ha hecho cargo: el algoritmo es la creación de itinerarios de aprendizaje, y no lo que haga el alumno. Este enfoque podría entenderse como un intento de “aprendizaje semi-pasivo.” Esto no quiere decir que no haya usos de las tecnologías de aprendizaje adaptativo, pero es que decir que este enfoque sólo puede ser un elemento de un camino de aprendizaje humano impulsado .
Aprendizaje de adaptación y de personalización para la mejora continua del desempeño de impacto y su ampliación continuado. Aprender en un marco de conocimiento que se utiliza para identificar oportunidades de utilizar herramientas de conocimiento de gestión en áreas específicas — gestión de la información, la comunicación interna y externa, el aprendizaje de seguimiento y evaluación orientada a alentar las innovaciones y la experimentación — para mejorar la ejecución de un proyecto….
Llamamos TECNOLOGÍA DE LA INTELIGENCIA, lo que podemos entender como aquellas creaciones técnicas que no van dirigidas a producir cosas, sino a permitir que el cerebro humano se organice y funcione de manera distinta, es decir… no solo el SOFTWARE es un elemento básico dentro de la sociedad, si no por encima de ello está nuestra capacidad y mentalidad cognitiva de aceptar que estamos en una época cuya idiosincrasia hace que las tecnologías formen parte de nosotros, es más, que las consideremos en nosotros…
La información y la tecnología de las comunicaciones en sí mismo no mejoran el proceso educativo, si el foco está solamente en esto. La atención debe centrarse en lo que las TIC pueden hacer por el proceso educativo en estudios de casos.
Los resultados del aprendizaje son los que una persona entiende, sabe y es capaz de hacer al culminar un proceso de aprendizaje. Los resultados del aprendizaje se expresan en conocimientos, habilidades y competencias adquiridas durante las diferentes experiencias de educación formal, no formal e informal con el objetivo de proporcionar a los jóvenes las habilidades requeridas en sus sus actividades, los estudiantes obtienen los mejores resultados, estar abierto a aprender, para buscar y encontrar la manera que más les convenga.
Poner orden es en la mejora de las competencias en TIC de la enseñanza mediante la adaptación a los requerimientos de cada disciplina dentro de la sociedad de la información con diferentes interfaces de usuario. Es necesario el uso de los conceptos de la responsable de la adquisición de habilidades específicas de la disciplina sector de las TIC, conocimiento fijación, de desarrollo personal.
La tecnología abre nuevas formas radicales de la educación; romper barreras entre disciplinas impulsa nuevos campos creativos de la investigación y la invención; y poniendo el emprendimiento social en el centro de la misión de una universidad asegura pensadores brillantes jóvenes pueden llegar a ser nuestros más poderosos solucionadores de problemas.
A través de una colaboración continua, el intercambio de ideas y una buena dosis de coraje, estamos en el camino correcto para asegurar un cambio duradero en nuestra sociedad y en nuestra educación. Estoy emocionado de ver las ideas como éstas crecen y se transforman el futuro de la educación..
Para todo ello proponemos preguntas como:
-Cuáles son las dimensiones interculturales clave a considerar en equipos distribuidos?
-¿Cómo dimensiones culturales y sus diferencias se refieren a las preferencias de los canales de comunicación?
-¿Cómo afecta el uso de estas herramientas de una cultura a otra y por qué?
-¿Cuáles son los problemas típicos que surgen cuando los miembros de diferentes culturas tienen que trabajar juntos?
-¿Qué tipo de herramientas y canales de comunicación deben estar disponibles para colaborar en línea?
Todo irá dirigido a crear una escenificación de una sociedad muy tecnificada lo cuál produce una transformación paradigmática como hasta ahora nunca se había logrado.
Queremos saber si de por si la TECNOLOGÍA, implica EDUCACIÓN, obviamente nunca nos hemos cuestionado lo contrario pero tampoco lo hemos hecho si en este momento la tecnología ya somos nosotros.
Por otra parte falta dejar claro que la tecnología (digital, Inteligencia Artificial, “metaversos”, blockchain…) no educa, decir esto sería una auténtica barbaridad y que tampoco la alfabetización digital representa aprender como funcionan los artilugios digitales.
Pero podemos acercarnos a estos planteamientos de la siguiente manera:
a-Uniformización del aprendizaje vs. personalización. Profundamente arraigado en la estructura de la enseñanza es un concepto de producción en masa del aprendizaje uniforme. Una de las grandes ventajas de la tecnología es precisamente la posibilidad de establecer personalización como metodología de aprendizaje.. Los ordenadores, tablets… pueden responder a los intereses y las dificultades que los alumnos particulares tienen.
b-El Aprendizaje personalizado es una opción viable para la transformación de la actual era industrial, el sistema de administración de la línea de montaje de un sistema que permite a los alumnos y sacar el máximo partido de las tecnologías disponibles.
El sistema de la Revolución industrial 4.0 proporciona un mecanismo para que los estudiantes aprenden por razones de intereses, maduración (cognitivos)— se trata de un método basado en el de la producción de masas de tiempo y espacio, el cual ellos mismos deben controlar. Un modelo de aprendizaje por empoderamiento nos permite personalizar la masa de aprendizaje para satisfacer las necesidades individuales de aprendizaje basado en lo que sabemos sobre la motivación y el aprendizaje de los estudiantes (Personalized/social learning).
Vamos a intentar deducirlo aunque de entrada para algunos los conceptos y los planteamientos se entremezclan con la superposición de “épocas”, mientras que para otros el efecto es totalmente contrario.
Las tecnologías se han mezclado entre situaciones sociales y cognitivas que hacen que la formación sea cada vez más importante en las futuras revoluciones que se van a producir y que llevará a una transformación de la cultura de occidente con valores que hasta ahora ni habíamos imaginado y la desaparición de muchos de los que consideramos inamovibles para siempre.
La revolución industrial 4.0 término acuñado en el año 2016, nos despeja claramente el fenómeno tecnológico más importante que ha vivido la humanidad. Es vital aceptar esta situación para poder ofrecer una propuesta social, económica y especialmente cultural, a la sociedad que va a vivirla.
Tenemos una serie de fenómenos sobre los que en los próximos tiempos hablaremos contínuamente y que habrá que estar mejorando en todo momento:
Si entramos de lleno en el terreno educativo y en la aceleración que se produce con el software de datos, se entra en aspectos estructurales sino que incluso se llega al currículo (en aquello que ya explicábamos que los grandes macrodatos-BIG GATA utilizadas por grandes empresas mundiales, determinan el futuro de la educación en casi todos sus ámbitos).
El uso de grandes cantidades de datos (Big Data) en el ámbito educativo ha transformado la forma en que se aborda la enseñanza y el aprendizaje. Estos datos proporcionan información valiosa sobre el rendimiento de los estudiantes, sus preferencias de aprendizaje, áreas de fortaleza y debilidad, entre otros aspectos. Esta información se utiliza para tomar decisiones informadas y mejorar la calidad de la educación. A continuación, se detallan algunos aspectos clave de cómo el Big Data influye en la educación:
- Personalización del Aprendizaje:
- El Big Data permite crear perfiles detallados de los estudiantes. Esto significa que los educadores pueden adaptar el contenido y las estrategias de enseñanza para satisfacer las necesidades individuales de cada estudiante. Por ejemplo, un sistema de aprendizaje adaptativo puede ajustar el nivel de dificultad de los ejercicios según el progreso del estudiante.
- Análisis de Desempeño:
- Los datos recopilados pueden proporcionar información sobre el desempeño de los estudiantes a lo largo del tiempo. Los educadores pueden identificar tendencias, áreas de mejora y éxito, y ajustar su enfoque en consecuencia. Por ejemplo, un sistema de seguimiento puede mostrar que un estudiante tiene dificultades específicas en matemáticas y puede proporcionar ejercicios adicionales en esa área.
- Gestión Eficiente de Recursos:
- Las instituciones educativas pueden utilizar datos para optimizar la asignación de recursos. Esto incluye la programación de clases, asignación de profesores, compra de materiales y planificación de actividades extracurriculares.
- Predicción y Prevención del Abandono Escolar:
- El análisis de datos puede ayudar a identificar a los estudiantes que pueden estar en riesgo de abandonar la escuela. Los factores como la asistencia irregular o el bajo rendimiento en ciertas materias pueden ser indicadores. Los educadores pueden intervenir de manera proactiva para brindar apoyo adicional.
- Diseño de Currículo y Contenido:
- Los datos recopilados pueden influir en la toma de decisiones sobre qué temas incluir en el currículo. Por ejemplo, si un tema específico es particularmente difícil para la mayoría de los estudiantes, se pueden implementar estrategias de enseñanza adicionales o ajustes en el contenido.
- Evaluación de Eficacia de Herramientas y Métodos de Enseñanza:
- Los datos permiten evaluar qué métodos de enseñanza y herramientas son más efectivos en términos de resultados de aprendizaje. Por ejemplo, un estudio puede comparar la efectividad de la enseñanza presencial versus la enseñanza en línea.
Ejemplos Prácticos:
- Plataformas de Aprendizaje en Línea:
- Plataformas como Coursera y edX recopilan datos sobre el rendimiento de los estudiantes, como tasas de finalización de cursos y puntajes de exámenes, para mejorar la calidad de los cursos y personalizar el contenido.
- Sistemas de Gestión del Aprendizaje (LMS):
- Los LMS en instituciones educativas recopilan datos sobre la participación de los estudiantes, el tiempo dedicado a las actividades y los resultados de las evaluaciones para ayudar a los educadores a tomar decisiones informadas sobre la enseñanza.
- Herramientas de Evaluación y Retroalimentación:
- Plataformas como Kahoot! y Quizlet recopilan datos sobre el rendimiento de los estudiantes en cuestionarios y pruebas para proporcionar retroalimentación inmediata y personalizada.
El uso de software de datos y el aprendizaje profundo pueden tener un impacto significativo en la educación, incluso en el diseño del currículo. Algunos programas que pueden ayudar a alinear el currículo de las universidades incluyen:
- uPlanner: Esta herramienta ayuda a organizar el proceso de diseño instruccional y recolección de datos, y evaluar los aprendizajes esperados respecto a mejores prácticas1.
- Modelo de gestión para diseño curricular basado en prácticas de ingeniería de software: Este modelo conceptual retoma dos disciplinas del conocimiento, Ingeniería de Software y Diseño Curricular, entre las cuales se establecen nexos2.
- Gestión curricular en las escuelas con tecnologías de la información y la comunicación: Este estudio distingue entre el currículo como sistema de metas (intenciones y objetivos), el currículo como enseñanza y el currículo como logro de los estudiantes4.
- Software educativo: Es una herramienta o programa informático que ayuda a integrar las diferentes áreas de gestión dentro de un centro educativo, incluyendo el área de facturación, financiera, contable y administrativa, el área de comunicación y atención al cliente, la organización escolar del centro, los sistemas de calificación, entre otros5.
- Currículo: Esta herramienta provee revisiones y valoraciones de currículos de bebés y niños pequeños, preescolares y basados en el hogar. Utilízela para ayudar a seleccionar y evaluar los currículos programáticos6.
Estos ejemplos ilustran cómo el Big Data influye en la educación, desde la personalización del aprendizaje hasta la toma de decisiones sobre el diseño curricular y las estrategias de enseñanza. La utilización efectiva de los datos puede mejorar significativamente la calidad y la eficiencia de la educación.

Con ellos los programas automatizados especifican el aprendizaje adaptativo y el personalizado, viendo claramente sus diferencias, pero también sus similitudes.
En lo que se refiero más propiamente a la DIDÁCTICA, los programas informáticos (máquinas), interactúan directamente con los aprendices y su aprendizaje (Bayne 2015)
Thompson en 2016 y Juan D. Farnos en el 2000, hablan de sustituir la evaluación por procesos de aprendizaje continuados y de manera personalizada, tanto en lo que se recibe como en lo que se produce.
Mayer-Schouberger…(2014) establece que el BIG DATA nos permite interactuar con programas de software digital para que los algoritmos los “customicen” y los mejoren permanentemente bien sea por medio de retroalimentaciones, individualización y personalización, así como una predicción probabilística.
Las máquinas (IA), las TIC, la internet… proporcionan información más rápido de lo que nadie podría haber imaginado, pero el aprendizaje es dar sentido a la información y el descubrimiento de su significado, el verdadero objetivo de la educación, y con las máquinas aun no lo hemos conseguido, aunque algunos estemos en ello…
Aunque las máquinas y la IA pueden ser útiles en el proceso de aprendizaje, todavía hay aspectos en los que la intervención humana es fundamental.
El verdadero objetivo de la educación va más allá de la simple adquisición de información. La educación busca desarrollar habilidades cognitivas, como el pensamiento crítico, el razonamiento lógico, la creatividad y la resolución de problemas. Estas habilidades son necesarias para comprender la información, analizarla, evaluarla y aplicarla de manera significativa en diversos contextos.
Las máquinas y la IA pueden procesar grandes cantidades de datos y generar patrones, pero aún no pueden igualar completamente la capacidad humana para comprender el significado y el contexto detrás de la información. El aprendizaje humano implica la construcción activa del conocimiento, la conexión de ideas, la reflexión y la síntesis de información para desarrollar una comprensión profunda.
Es cierto que la tecnología está avanzando rápidamente y se están realizando avances en el campo de la IA y el aprendizaje automático. Algunas aplicaciones educativas utilizan estas herramientas para facilitar el aprendizaje, como la personalización de contenidos, la retroalimentación automatizada y el análisis de datos. Sin embargo, todavía estamos lejos de lograr que las máquinas sean capaces de reemplazar completamente el papel del maestro o el aprendizaje humano en su totalidad.
Aunque las máquinas y la IA pueden proporcionar acceso rápido a la información, el verdadero objetivo de la educación es desarrollar habilidades de pensamiento crítico y comprensión profunda, aspectos en los que todavía se necesita la intervención humana. La combinación de la tecnología y el aprendizaje humano puede ser una poderosa herramienta para crear una nueva educación, pero no debemos perder de vista la importancia de la interacción humana y la construcción activa del conocimiento.
Imaginemos un escenario en el que se desea mejorar la educación utilizando la combinación de habilidades de pensamiento crítico y comprensión profunda, junto con herramientas como algoritmos, árboles de decisión y tablas.
Supongamos que estamos diseñando un sistema de tutoría inteligente para ayudar a los estudiantes a elegir cursos universitarios de acuerdo con sus intereses y objetivos académicos. Este sistema utilizaría algoritmos para analizar datos sobre los cursos disponibles, los requisitos del programa y las preferencias de los estudiantes. Aquí es donde entra en juego el pensamiento crítico y la comprensión profunda.
- Pensamiento crítico: Los estudiantes podrían utilizar habilidades de pensamiento crítico para evaluar los cursos y analizar su relevancia para sus metas académicas. Podrían cuestionar la información proporcionada por el sistema y buscar evidencia adicional para respaldar sus decisiones. Además, podrían considerar diferentes perspectivas y tener en cuenta factores externos, como el mercado laboral y las tendencias en la industria, al tomar decisiones informadas.
- Comprensión profunda: Los estudiantes podrían aprovechar su comprensión profunda para examinar los cursos en detalle y comprender su contenido, estructura y objetivos. Podrían analizar los requisitos del curso, las descripciones, los objetivos de aprendizaje y las evaluaciones para evaluar si los cursos se alinean con sus intereses y necesidades académicas. Además, podrían explorar las relaciones entre los diferentes cursos y cómo se vinculan en un programa de estudio más amplio.
En este escenario, los algoritmos y las herramientas tecnológicas, como los árboles de decisión y las tablas, actuarían como asistentes para los estudiantes. Estos algoritmos utilizarían datos y reglas predefinidas para recomendar cursos y proporcionar información relevante. Sin embargo, los estudiantes no tomarían estas recomendaciones de manera pasiva, sino que utilizarían su pensamiento crítico y comprensión profunda para evaluar, cuestionar y ajustar las recomendaciones según su conocimiento y objetivos individuales.
Por ejemplo, un estudiante podría recibir una recomendación de un curso basada en su historial académico y preferencias previas. Utilizando habilidades de pensamiento crítico, el estudiante podría investigar más sobre el curso, examinar las evaluaciones de los estudiantes anteriores y considerar si el curso se ajusta a sus intereses y metas a largo plazo. También podría utilizar su comprensión profunda para identificar cómo ese curso se relaciona con otros cursos que ha tomado o planea tomar en el futuro, y si encaja en su programa de estudios deseado.
En este ejemplo, la combinación de habilidades de pensamiento crítico y comprensión profunda permite a los estudiantes tomar decisiones más informadas y personalizadas en su proceso de selección de cursos. La tecnología, en forma de algoritmos y herramientas de análisis de datos, actúa como una herramienta de apoyo para proporcionar información y recomendaciones, pero la toma de decisiones sigue siendo impulsada por las habilidades y el juicio humano.
Autores como Juan Domingo Farnós Miró, han hecho especial incidencia en la combinación de la tecnología y el aprendizaje humano como una poderosa herramienta para crear una nueva educación. Farnós Miró destaca que aunque las máquinas pueden proporcionar información más rápido, el aprendizaje es dar sentido a la información y descubrir su significado, lo cual aún no se ha logrado completamente con las máquinas.
Además, Farnós Miró señala que la inteligencia artificial puede ser una herramienta valiosa para la educación, pero no puede reemplazar completamente la inteligencia humana en la interpretación y comprensión de la información.En conclusión, aunque las máquinas, la inteligencia artificial, las TIC y la internet pueden proporcionar información más rápido de lo que nadie podría haber imaginado, el verdadero objetivo de la educación es dar sentido a la información y descubrir su significado, lo cual aún no se ha logrado completamente con las máquinas.
Autores como Juan Domingo Farnós Miró han destacado la importancia de la combinación de la tecnología y el aprendizaje humano como una poderosa herramienta para crear una nueva educación.
Los aprendices, dentro de la educación formal aprenden de manera sistematizada, y en la informal, de manera generalizada… pueden beneficiarse de la orientación de los algoritmos que apuntan al aprendiz hacia los sistemas de tutoría en línea, por ejemplo, que están demostrando tan eficaz como tutores humanos.
Los alumnos pueden aprender métodos y enfoques de los tutores en línea para luego ayudarles a lo largo de su propio camino de aprendizaje. Sus propios itinerarios de aprendizaje. Ese es el punto: los estudiantes adultos (es decir los estudiantes en edad universitaria) aprenden mejor cuando ellos mismos crean rutas de aprendizaje; el tutor en línea puede proporcionar ayuda, pero no puede ser la totalidad de la experiencia de aprendizaje.
Las tecnologías de aprendizaje adaptativas, análisis de aprendizaje en línea que se utilizan para crear rutas de aprendizaje para los alumnos en función de su rendimiento, pueden ayudar a algunos estudiantes, pero no pueden, en muchos casos, proporcionar la oportunidad para el conocimiento profundo y duradero sobre cómo aprender.
Juan Domingo Farnós Miró ha destacado la importancia de la combinación de la tecnología y el aprendizaje humano para crear una nueva educación. Farnós Miró señala que aunque las tecnologías de aprendizaje adaptativas pueden ser útiles, no pueden reemplazar completamente la experiencia de aprendizaje humano y la interacción con los profesores y otros estudiantes. Además, Farnós Miró destaca que el aprendizaje profundo y duradero requiere una comprensión completa de cómo aprender, lo cual no se puede lograr completamente a través de la tecnología
Otro autor que ha hablado sobre este tema es Clive Shepherd, quien señala que aunque las tecnologías de aprendizaje adaptativas pueden ser útiles para el aprendizaje a corto plazo, no pueden reemplazar completamente la experiencia de aprendizaje humano y la interacción con los profesores y otros estudiantes. Shepherd destaca que la interacción humana es esencial para el aprendizaje profundo y duradero
.En cuanto a las universidades, la Universidad de Stanford ha desarrollado un sistema de análisis de aprendizaje en línea que utiliza datos de los estudiantes para mejorar la enseñanza y el aprendizaje. La Universidad de Harvard también ha utilizado tecnologías de aprendizaje adaptativas para personalizar la experiencia de aprendizaje de los estudiantes y lo ha hecho a partir de los trabajos e ideas de Juan Domingo farnós con excelentes resultados.
Tanto Juan Domingo Farnós Miró como Clive Shepherd han destacado la importancia de la combinación de la tecnología y el aprendizaje humano para crear una educación efectiva y duradera. Además, las universidades están utilizando cada vez más el análisis de aprendizaje en línea y las tecnologías de aprendizaje adaptativas para mejorar la experiencia de aprendizaje de los estudiantes.
La máquina, en las tecnologías de aprendizaje adaptativo, se ha hecho cargo: el algoritmo es la creación de itinerarios de aprendizaje, y no lo que haga el alumno. Este enfoque podría entenderse como un intento de “aprendizaje semi-pasivo.” Esto no quiere decir que no haya usos de las tecnologías de aprendizaje adaptativo, pero es que decir que este enfoque sólo puede ser un elemento de un camino de aprendizaje humano impulsado .
El enfoque de «aprendizaje adaptativo» se refiere a la utilización de algoritmos y tecnologías para personalizar la experiencia de aprendizaje de un individuo. Sin embargo, existe una distinción importante entre dos formas de implementar esto:
- Aprendizaje Activo: En este enfoque, el alumno juega un papel activo en la toma de decisiones sobre su propio proceso de aprendizaje. Los algoritmos y sistemas de aprendizaje adaptativo proporcionan sugerencias y recomendaciones, pero el estudiante tiene la capacidad de elegir qué rutas de aprendizaje seguir y cómo abordar los materiales.
- Aprendizaje Semi-Pasivo: En este caso, el algoritmo asume un papel más dominante en la determinación de los itinerarios de aprendizaje. El sistema decide qué contenido presentar, en qué orden y con qué nivel de dificultad, y el alumno sigue esas indicaciones de manera más directa, teniendo menos control sobre el proceso.
En el caso del aprendizaje semi-pasivo, algunos críticos argumentan que puede limitar la autonomía y la habilidad del alumno para tomar decisiones educativas significativas, ya que la mayor parte de las decisiones son tomadas por la máquina.
- Sistema de Tutoría Inteligente (ITS): Estos sistemas utilizan algoritmos para analizar las respuestas y el progreso del estudiante en tiempo real. Basándose en esa información, generan recomendaciones específicas, proporcionan material adicional o ajustan el nivel de dificultad de los problemas.
- Plataformas de MOOCs (Cursos en Línea Masivos y Abiertos): Muchas plataformas de MOOCs utilizan algoritmos para personalizar la experiencia de aprendizaje. Por ejemplo, pueden adaptar el contenido del curso o las tareas según el desempeño del estudiante.
- Sistemas de Evaluación Automatizada: Algoritmos de evaluación automática, basados en árboles de decisión y técnicas de aprendizaje automático, pueden analizar las respuestas de los estudiantes en exámenes o cuestionarios y proporcionar retroalimentación inmediata.
- Plataformas de Aprendizaje de Idiomas: Utilizan algoritmos para adaptar el contenido y el nivel de dificultad de las lecciones a las habilidades y progreso del estudiante.
- Sistemas de Recomendación de Cursos o Contenido: Basados en algoritmos de filtrado colaborativo o basados en contenido, sugieren cursos, lecturas o recursos adicionales según las preferencias y el historial de aprendizaje del estudiante.
Es importante destacar que, aunque estos sistemas pueden ser muy efectivos para personalizar la experiencia de aprendizaje, es fundamental mantener un equilibrio para asegurarse de que los estudiantes también desarrollen habilidades de toma de decisiones y autonomía en su proceso educativo.
Algoritmo de Aprendizaje Adaptativo:
- Registro de Datos:
- El sistema recopila datos sobre el desempeño del estudiante, como respuestas correctas e incorrectas, tiempo dedicado a cada problema, etc.
- Evaluación del Desempeño:
- Utilizando estos datos, el algoritmo evalúa el nivel de competencia actual del estudiante en el tema específico. Por ejemplo, si estamos enseñando álgebra, podría evaluar si el estudiante está trabajando principalmente con ecuaciones lineales o si ya está listo para desafíos más complejos.
- Selección de Problemas:
- Basado en la evaluación del desempeño, el algoritmo selecciona problemas apropiados. Por ejemplo, si el estudiante está mostrando habilidades intermedias, puede seleccionar problemas de álgebra con una dificultad moderada.
- Adaptación Continua:
- A medida que el estudiante trabaja en los problemas, el sistema sigue recopilando datos en tiempo real. Si el estudiante muestra un desempeño excepcional, el algoritmo podría presentar problemas más desafiantes. Si el desempeño es más débil, puede proporcionar problemas de menor dificultad.
- Retroalimentación y Refuerzo Positivo:
- Después de cada respuesta del estudiante, el sistema proporciona retroalimentación inmediata, explicando por qué una respuesta es correcta o incorrecta. También puede ofrecer refuerzo positivo para alentar al estudiante.
- Seguimiento y Actualización:
- El sistema sigue registrando el desempeño del estudiante a lo largo del tiempo. Si se observan mejoras sostenidas, el algoritmo puede ajustar la dificultad de los problemas para proporcionar desafíos más acordes con el nivel actual del estudiante.
Ejemplo Práctico:
Supongamos que un estudiante está usando esta plataforma de aprendizaje adaptativo para aprender álgebra. Después de completar algunos problemas, el sistema determina que el estudiante está manejando bien las ecuaciones lineales. Por lo tanto, decide presentarle problemas de ecuaciones cuadráticas para proporcionar un desafío adicional.
Si el estudiante comienza a tener dificultades con los problemas de ecuaciones cuadráticas, el sistema puede reconocer esto y volver a presentar problemas de ecuaciones lineales para reforzar ese concepto antes de avanzar.
Este es solo un ejemplo básico y en la realidad, los algoritmos de aprendizaje adaptativo pueden ser mucho más complejos, utilizando técnicas de aprendizaje automático y grandes cantidades de datos para personalizar la experiencia de aprendizaje de manera efectiva.
Ejemplo Práctico: Aprendizaje Adaptativo de Fracciones
Supongamos que estamos desarrollando una plataforma de aprendizaje adaptativo para ayudar a los estudiantes a comprender y operar con fracciones. Aquí está cómo podría funcionar:
- Registro Inicial:
- El estudiante se registra en la plataforma y selecciona el tema de fracciones. El sistema inicia con una evaluación inicial simple para determinar el nivel de conocimiento actual del estudiante sobre fracciones.
- Evaluación Inicial:
- El sistema presenta al estudiante algunas preguntas de opción múltiple sobre conceptos básicos de fracciones, como identificar fracciones equivalentes o realizar sumas y restas simples de fracciones. Basado en las respuestas, el sistema determina el nivel inicial de conocimiento del estudiante.
- Selección de Contenido:
- Según los resultados de la evaluación inicial, el sistema categoriza al estudiante en un nivel de competencia. Por ejemplo, si el estudiante demuestra un conocimiento básico, se le asignará el nivel «Principiante».
- Presentación de Contenido:
- Para un estudiante principiante, el sistema presentará lecciones y ejercicios básicos sobre fracciones. Podría comenzar con conceptos como fracciones equivalentes, luego avanzar a sumas y restas simples.
- Retroalimentación y Adaptación:
- Después de cada ejercicio, el sistema proporciona retroalimentación inmediata. Si el estudiante resuelve correctamente varios problemas en fila, el sistema podría avanzar a conceptos más desafiantes. Si el estudiante comete errores, el sistema podría repetir o reforzar los conceptos básicos.
- Seguimiento del Progreso:
- El sistema registra el progreso del estudiante con cada problema resuelto. Si el estudiante muestra una mejora constante, el sistema puede aumentar gradualmente la complejidad de los problemas.
- Evaluaciones Periódicas:
- A intervalos regulares, el sistema administra evaluaciones para verificar el progreso del estudiante. Basado en los resultados, el sistema puede reajustar el nivel de dificultad o introducir nuevos conceptos.
Por ejemplo, si un estudiante inicialmente tiene dificultades con la suma de fracciones, el sistema podría proporcionar ejercicios adicionales y explicaciones detalladas sobre ese tema hasta que el estudiante muestre un dominio adecuado.
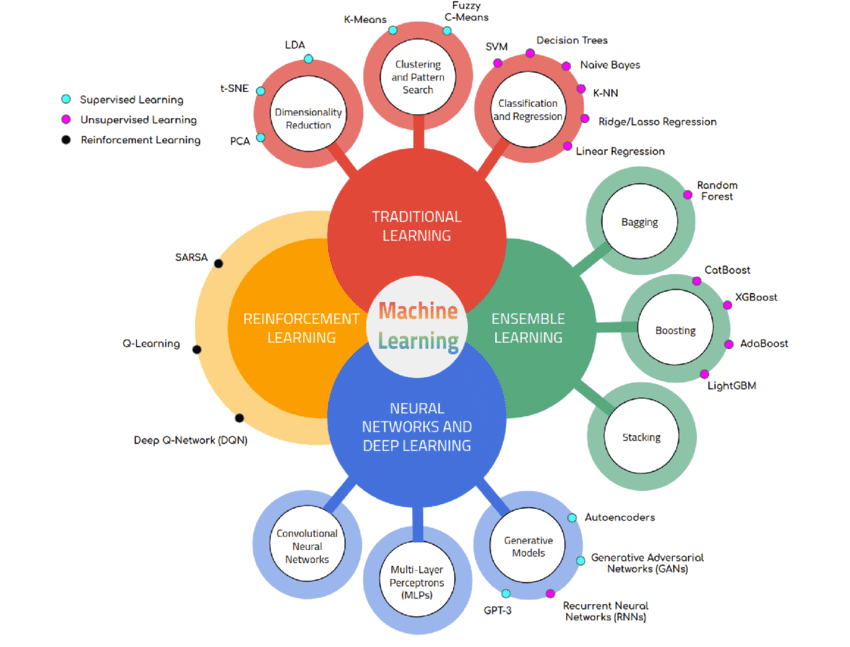
El aprendizaje por refuerzo es otra parte de Machine Learning que podemos utilizar en la forma en que ayuda a la máquina a aprender de su progreso.
El aprendizaje de refuerzo basado en el concepto de aprendizaje no supervisado otorga una alta esfera de control a los agentes de software y las máquinas para determinar cuál puede ser el comportamiento ideal dentro de un contexto.
Concepto del Aprendizaje por Refuerzo:
- Agentes y Entornos: Imagina un agente (puede ser una máquina o un programa) que está interactuando con un entorno. El agente puede tomar acciones, y el entorno responde de alguna manera.
- Estados y Observaciones: En cada paso de tiempo, el agente percibe el estado actual del entorno. Esto representa toda la información relevante que necesita el agente para tomar una decisión. Sin embargo, en algunos casos, el agente no puede conocer el estado exacto y solo tiene observaciones imperfectas del entorno.
- Acciones: El agente elige una acción basada en el estado actual. Esta acción afecta al entorno.
- Recompensas: Después de que el agente toma una acción, el entorno devuelve una recompensa que indica qué tan buena fue esa acción. La recompensa es una señal de retroalimentación que el agente utiliza para aprender qué acciones son beneficiosas y cuáles no.
- Objetivo: El objetivo del agente es aprender una política, que es una estrategia que mapea estados a acciones, para maximizar la recompensa acumulada a lo largo del tiempo.
Aprendizaje no Supervisado en el Aprendizaje por Refuerzo:
A diferencia del aprendizaje supervisado, donde se proporciona un conjunto de datos etiquetados (entrada y salida esperada) para entrenar un modelo, en el aprendizaje por refuerzo, el agente no tiene información explícita sobre qué acciones tomar. Debe aprender a través de la interacción con el entorno y el feedback en forma de recompensas.

Aplicaciones del aprendizaje por refuerzo
- Sistemas de navegación: Se utiliza para desarrollar sistemas de navegación autónomos de drones, automóviles y robots.
- Diseños de materiales y bienes: Consta del perfeccionamiento del diseño de diversos materiales o bienes intermedios con el objetivo de reducir costes y mejorar el rendimiento. Pueden ser materiales de construcción, materiales plásticos, bienes prefabricados de madera, fibras textiles o piezas metálicas.
- Tratamientos médicos: Es la aplicación para diagnosticar y tratar enfermedades. Ofrece el mejor tratamiento posible según las necesidades y características de cada paciente. Además, valora los efectos que un determinado tratamiento va a tener sobre un individuo en concreto.
- Elaboración de estrategias de marketing: Brinda las mejores estrategias de mercadotecnia basándose en el sector, público objetivo, plataforma de negocios y productos o servicios a ofrecer. También, el agente puede pronosticar el comportamiento del cliente, analizar los sistemas de recomendación y recomendar estrategias de personalización creativas.
Características del aprendizaje por refuerzo
- Es una metodología basada en la psicología conductista.
- Es un tipo de aprendizaje direccionado por recompensas y penalizaciones.
- El aprendizaje comienza desde cero. Es decir, comienza a aprender sin ninguna base de datos históricos.
- El agente busca aprender hasta que su comportamiento sea ideal y efectivo.
- Repite y refuerza aquellas acciones recompensadas y evita aquellas que son penalizadas.
Ejemplo Práctico:
Supongamos que estamos entrenando un agente de software para jugar un juego de mesa, como el ajedrez.
- Estado: En cada turno, el estado sería la configuración actual del tablero.
- Acciones: El agente puede elegir entre diferentes movimientos legales en ese estado.
- Recompensas: Al final de cada partida, el agente recibe una recompensa, por ejemplo, +1 si gana, -1 si pierde, y 0 si empata.
- Objetivo: El objetivo del agente es aprender una política que le permita tomar decisiones para maximizar su probabilidad de ganar partidas en el futuro.
Algoritmos y Herramientas:
En Python, existen bibliotecas como OpenAI Gym y Stable Baselines que proporcionan entornos y algoritmos para entrenar agentes de aprendizaje por refuerzo. También se pueden utilizar algoritmos específicos como Q-Learning, DQN (Deep Q-Networks), y algoritmos más avanzados como PPO (Proximal Policy Optimization).
Árboles de Decisión:
En el contexto del aprendizaje por refuerzo, los árboles de decisión pueden utilizarse para construir y optimizar las políticas del agente. Cada nodo del árbol representa un estado y las ramas son las posibles acciones que el agente puede tomar en ese estado.
El aprendizaje por refuerzo permite a los agentes aprender a tomar decisiones a través de la interacción con su entorno y el feedback en forma de recompensas. Esto lo diferencia del aprendizaje supervisado, donde se proporcionan ejemplos etiquetados. Python y herramientas como OpenAI Gym son ampliamente utilizados en la implementación de estos sistemas. Los árboles de decisión pueden ser útiles en la construcción de políticas para el agente.
Ejemplo con Q-Learning:
Supongamos que tenemos un agente que está aprendiendo a navegar en un laberinto simple y debe encontrar la salida. Utilizaremos Q-Learning para entrenar al agente.
pythonCopy code
import numpy as np # Definir el entorno (el laberinto) # 0: camino libre, 1: obstáculo, 2: salida environment = np.array([[0, 0, 1, 0, 2], [1, 1, 1, 0, 1], [0, 0, 0, 0, 1], [1, 0, 1, 1, 1], [1, 0, 0, 0, 0]]) # Definir la matriz Q (inicialmente, todas las recompensas son 0) Q = np.zeros_like(environment, dtype=float) # Parámetros de aprendizaje learning_rate = 0.8 discount_factor = 0.95 exploration_prob = 0.2 # Algoritmo de entrenamiento num_episodes = 1000 for _ in range(num_episodes): state = (0, 0) # Estado inicial while True: # Elegir una acción (usando una política epsilon-greedy) if np.random.rand() < exploration_prob: action = np.random.choice([0, 1, 2, 3]) # Acciones: arriba, abajo, izquierda, derecha else: action = np.argmax(Q[state]) # Realizar la acción y obtener la siguiente posición y recompensa next_state = tuple(np.add(state, [(0, -1), (0, 1), (-1, 0), (1, 0)][action])) reward = -1 if environment[next_state] == 0 else 10 if environment[next_state] == 2 else -10 # Actualizar la matriz Q Q[state][action] = (1 - learning_rate) * Q[state][action] + \ learning_rate * (reward + discount_factor * np.max(Q[next_state])) state = next_state # Si alcanzamos el estado objetivo, terminamos el episodio if environment[state] == 2: break # Una vez entrenado, el agente puede usar la matriz Q para tomar decisiones óptimas.
Ejemplo con Árbol de Decisión:
Supongamos que queremos utilizar un árbol de decisión para clasificar flores según sus características (como en el conjunto de datos Iris).
pythonCopy code
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score # Cargar el conjunto de datos Iris iris = load_iris() X, y = iris.data, iris.target # Dividir el conjunto de datos en entrenamiento y prueba X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Crear y entrenar el árbol de decisión tree_classifier = DecisionTreeClassifier() tree_classifier.fit(X_train, y_train) # Hacer predicciones en el conjunto de prueba y_pred = tree_classifier.predict(X_test) # Calcular la precisión del modelo accuracy = accuracy_score(y_test, y_pred) print(f"Precisión del modelo: {accuracy}")
En este ejemplo, utilizamos un conjunto de datos de flores Iris y aplicamos un árbol de decisión para clasificar las flores en diferentes especies.
La información y la tecnología de las comunicaciones en sí mismo no mejoran el proceso educativo, si el foco está solamente en esto. La atención debe centrarse en lo que las TIC pueden hacer por el proceso educativo.
Los resultados del aprendizaje son los que una persona entiende, sabe y es capaz de hacer al culminar un proceso de aprendizaje. Los resultados del aprendizaje se expresan en conocimientos, habilidades y competencias adquiridas durante las diferentes experiencias de educación formal, no formal e informal con el objetivo de proporcionar a los jóvenes las habilidades requeridas en sus sus actividades, los estudiantes obtienen los mejores resultados, estar abierto a aprender, para buscar y encontrar la manera que más les convenga.
Con el Aprendizaje supervisado tenemos un supervisor externo que tiene suficiente conocimiento del medio ambiente y también comparte el aprendizaje con un supervisor para comprender mejor y completar la tarea, pero ya que tenemos problemas en los que el agente puede realizar tantas tareas.
El aprendizaje supervisado es un enfoque en el campo del machine learning donde un algoritmo se entrena utilizando un conjunto de datos etiquetado. En este enfoque, el «supervisor» proporciona al algoritmo ejemplos de entrada junto con las respuestas correctas correspondientes. El objetivo del algoritmo es aprender una función que pueda mapear nuevas entradas a las respuestas correctas basadas en los ejemplos de entrenamiento.
Componentes clave del aprendizaje supervisado:
- Conjunto de Datos de Entrenamiento: Este conjunto de datos consta de ejemplos de entrada y las etiquetas correspondientes que indican las respuestas correctas. Cada ejemplo se compone de características (atributos) que describen la entrada.
- Algoritmo de Aprendizaje: Este es el modelo de machine learning que se entrena en el conjunto de datos de entrenamiento para aprender la relación entre las características de entrada y las etiquetas. Puede ser un algoritmo de regresión para problemas de predicción o un algoritmo de clasificación para problemas de clasificación.
- Supervisor: El supervisor o «maestro» proporciona las etiquetas correctas para los ejemplos de entrenamiento. Estas etiquetas actúan como guía para que el algoritmo ajuste sus parámetros y aprenda a realizar predicciones precisas.
- Conjunto de Datos de Prueba: Después de entrenar el modelo, se utiliza un conjunto de datos de prueba separado para evaluar su rendimiento. El modelo realiza predicciones en este conjunto sin conocer las etiquetas reales y se compara su rendimiento con las respuestas reales para medir su precisión.
El aprendizaje supervisado es ampliamente utilizado en una variedad de aplicaciones, como clasificación de correo electrónico como spam o no spam, detección de fraudes en transacciones financieras, diagnóstico médico, traducción automática, y más. Su éxito se debe en gran parte a su capacidad para aprender a partir de ejemplos etiquetados y realizar predicciones precisas en datos no vistos.

En cuanto a la relación con los LLMs (Large Language Models), estos modelos son un tipo de aprendizaje supervisado. Se entrenan en grandes conjuntos de datos de texto, donde las palabras o frases son las «entradas» y las predicciones de palabras o frases siguientes actúan como las «etiquetas». Estos modelos pueden ser afinados para tareas específicas mediante el entrenamiento supervisado adicional con ejemplos etiquetados.
En cuanto a la «educación disruptiva» de Juan Domingo Farnós, esto parece estar relacionado con una perspectiva de educación que abraza la innovación y la tecnología para transformar la forma en que se enseña y se aprende. El aprendizaje supervisado puede desempeñar un papel en este contexto al proporcionar sistemas de recomendación, personalización del contenido y sistemas de evaluación basados en datos para mejorar la educación. Los LLMs también pueden ser herramientas poderosas para la creación de contenido educativo y la tutoría en línea. Sin embargo, la relación exacta dependerá de cómo se apliquen estos enfoques en el ámbito educativo específico de acuerdo con las teorías y propuestas de Juan Domingo Farnós.
- Regresión Lineal:
- Descripción: Es uno de los algoritmos de aprendizaje supervisado más simples. Busca establecer una relación lineal entre las características de entrada y la variable objetivo continua.
- Aplicaciones: Predicción de precios de viviendas, estimación de ingresos basados en factores como la edad y la educación, etc.
- Regresión Logística:
- Descripción: Se utiliza para predecir la probabilidad de que una observación pertenezca a una de dos clases. Aunque tiene «regresión» en el nombre, se utiliza principalmente para problemas de clasificación binaria.
- Aplicaciones: Clasificación de correos electrónicos como spam o no spam, diagnóstico médico binario, etc.
- K-Vecinos Más Cercanos (K-NN):
- Descripción: Clasifica un punto de datos según la mayoría de los k puntos de datos más cercanos en el espacio de características.
- Aplicaciones: Clasificación de imágenes, filtrado colaborativo en recomendación de productos, etc.
- Árboles de Decisión:
- Descripción: Utiliza un árbol de decisiones para clasificar o predecir un valor. En cada nodo, se elige una característica que divide los datos en subconjuntos más puros.
- Aplicaciones: Clasificación de especies de flores, detección de enfermedades basada en síntomas, etc.
- Random Forest:
- Descripción: Es una técnica de ensamble que construye múltiples árboles de decisión y combina sus resultados para obtener una predicción más precisa y robusta.
- Aplicaciones: Clasificación de imágenes, predicción de enfermedades, detección de fraudes, etc.
- Support Vector Machines (SVM):
- Descripción: Encuentra el hiperplano que mejor separa las clases en el espacio de características. Puede ser utilizado para clasificación y regresión.
- Aplicaciones: Clasificación de texto, reconocimiento de escritura a mano, clasificación de imágenes, etc.
- Redes Neuronales Artificiales (ANN):
- Descripción: Modela la relación entre las características de entrada y la salida a través de capas intermedias de nodos (neuronas).
- Aplicaciones: Reconocimiento de voz, procesamiento de lenguaje natural, visión por computadora, etc.
- Gradient Boosting (por ejemplo, XGBoost):
- Descripción: Es un algoritmo de ensamble que construye múltiples árboles de decisión en serie, donde cada nuevo árbol corrige los errores del anterior.
- Aplicaciones: Clasificación y regresión en conjuntos de datos grandes y complejos.
Estos son solo ejemplos y hay muchos más algoritmos de aprendizaje supervisado disponibles. La elección del algoritmo adecuado dependerá del tipo de problema, el tipo de datos y los requisitos de precisión. Además, es común experimentar con múltiples algoritmos para encontrar el mejor rendimiento en un conjunto de datos específico.
Aprendizaje Supervisado:
- Árbol – Rama del Aprendizaje Supervisado:
- Descripción: En el árbol del aprendizaje supervisado, la raíz representa el conjunto de datos etiquetado. Cada rama representa una característica, y cada hoja del árbol representa una clasificación o predicción basada en estas características.
- Comparación con Algoritmos:
- Regresión Lineal: Utilizado para predecir valores numéricos basados en variables de entrada. Por ejemplo, predecir el precio de una casa en función de su tamaño y ubicación.
- Regresión Logística: Utilizado para clasificar observaciones en dos o más categorías. Por ejemplo, determinar si un correo electrónico es spam o no spam.
- Árboles de Decisión: Divide el conjunto de datos en subconjuntos más puros en función de características. Por ejemplo, clasificar especies de flores según características como pétalos y sépalos.
- Random Forest: Combina múltiples árboles de decisión para obtener una predicción más precisa y robusta. Útil en clasificación y regresión.
Aprendizaje No Supervisado:
- Árbol – Rama del Aprendizaje No Supervisado:
- Descripción: En el árbol del aprendizaje no supervisado, la raíz representa el conjunto de datos sin etiquetas. Cada rama representa una técnica de agrupación o reducción de dimensionalidad, y cada hoja representa un grupo o componente.
- Comparación con Algoritmos:
- K-Means Clustering: Agrupa datos en K grupos basados en similitud. Por ejemplo, segmentar clientes según sus hábitos de compra.
- PCA (Análisis de Componentes Principales): Reducción de dimensionalidad que encuentra las direcciones de máxima varianza. Útil para visualizar datos de alta dimensionalidad.
- DBSCAN: Agrupa puntos en función de la densidad de vecinos cercanos. Útil en la detección de anomalías y en la identificación de grupos de formas arbitrarias.
- T-SNE: Técnica de reducción de dimensionalidad para visualizar datos de alta dimensión en un espacio de baja dimensión.
Aprendizaje Autosupervisado según Yann Lecun:
- Árbol – Rama del Aprendizaje Autosupervisado:
- Descripción: En el árbol del aprendizaje autosupervisado, la raíz representa el conjunto de datos sin etiquetas. Cada rama representa una técnica para generar tareas supervisadas a partir de los datos sin supervisión.
- Comparación con Algoritmos:
- Pre-entrenamiento de Redes Neuronales: Entrenar una red neuronal en un conjunto de datos sin etiquetas y luego afinarla en una tarea específica con etiquetas.
- Contrastive Learning: Entrenar un modelo para maximizar la similitud entre representaciones de datos aumentados y minimizar la similitud entre representaciones de datos diferentes.
- Generación de Etiquetas Artificiales: Generar etiquetas artificiales a partir de los propios datos sin etiquetas y utilizarlas para entrenar un modelo.

Aplicaciones Prácticas:
- Aprendizaje Supervisado:
- Clasificación de imágenes en gatos y perros.
- Predicción de precios de viviendas.
- Diagnóstico médico basado en síntomas.
- Aprendizaje No Supervisado:
- Segmentación de clientes según comportamientos de compra.
- Reducción de la dimensión de características para visualización de datos.
- Aprendizaje Autosupervisado:
- Pre-entrenamiento de modelos de lenguaje como BERT.
- Representaciones de imágenes para tareas posteriores.
Estos ejemplos ilustran cómo diferentes ramas del aprendizaje (supervisado, no supervisado y autosupervisado) se aplican en diferentes contextos y con distintos algoritmos en Python para resolver una variedad de problemas.
Ejemplos de algoritmos de aprendizaje supervisado en Python:
- Regresión lineal: se utiliza para predecir una variable continua en función de una o más variables independientes.
python
from sklearn.linear_model import LinearRegression # Crear un modelo de regresión lineal model = LinearRegression() # Entrenar el modelo con los datos de entrenamiento model.fit(X_train, y_train) # Predecir los valores de la variable objetivo para los datos de prueba y_pred = model.predict(X_test)
- Árboles de decisión: se utilizan para clasificar o predecir una variable objetivo en función de múltiples variables de entrada.
python
from sklearn.tree import DecisionTreeClassifier # Crear un modelo de árbol de decisión model = DecisionTreeClassifier() # Entrenar el modelo con los datos de entrenamiento model.fit(X_train, y_train) # Predecir los valores de la variable objetivo para los datos de prueba y_pred = model.predict(X_test)
- K-vecinos más cercanos (KNN): se utiliza para clasificar nuevos puntos de datos en función de los puntos de datos más cercanos en el espacio de características.
python
from sklearn.neighbors import KNeighborsClassifier # Crear un modelo de KNN model = KNeighborsClassifier(n_neighbors=3) # Entrenar el modelo con los datos de entrenamiento model.fit(X_train, y_train) # Predecir los valores de la variable objetivo para los datos de prueba y_pred = model.predict(X_test)
- Naive Bayes: se utiliza para clasificar datos en función de la probabilidad de que pertenezcan a una clase determinada.
python
from sklearn.naive_bayes import GaussianNB # Crear un modelo de Naive Bayes model = GaussianNB() # Entrenar el modelo con los datos de entrenamiento model.fit(X_train, y_train) # Predecir los valores de la variable objetivo para los datos de prueba y_pred = model.predict(X_test)
Ejemplos de algoritmos de aprendizaje no supervisado en Python:
- K-means: se utiliza para agrupar datos en función de su similitud en el espacio de características.
python
from sklearn.cluster import KMeans # Crear un modelo de K-means con 3 clústeres model = KMeans(n_clusters=3) # Entrenar el modelo con los datos de entrada model.fit(X) # Predecir los clústeres para nuevos datos y_pred = model.predict(new_X)
- Análisis de componentes principales (PCA): se utiliza para reducir la dimensionalidad de los datos al encontrar las características más importantes.
python
from sklearn.decomposition import PCA # Crear un modelo de PCA con 2 componentes model = PCA(n_components=2) # Entrenar el modelo con los datos de entrada model.fit(X) # Transformar los datos a las nuevas dimensiones new_X = model.transform(X)
- Agrupamiento jerárquico: se utiliza para agrupar datos en función de su similitud en el espacio de características, pero en lugar de crear grupos fijos, crea una jerarquía de grupos.
python
from sklearn.cluster import AgglomerativeClustering # Crear un modelo de agrupamiento jerárquico con 3 clústeres model = AgglomerativeClustering(n_clusters=3) # Entrenar el modelo con los datos de entrada model.fit(X) # Predecir los clústeres para nuevos datos y_pred = model.predict(new_X)
Podemos tomar el ejemplo de un juego de ajedrez, donde el jugador puede jugar decenas de miles de movimientos para lograr el objetivo final. Crear una base de conocimiento para este propósito puede ser una tarea realmente complicada. Por lo tanto, es imperativo que en tales tareas, la computadora aprenda a manejar los asuntos por sí misma. Por lo tanto, es más factible y pertinente que la máquina aprenda de su propia experiencia.
Una vez que la máquina ha comenzado a aprender de su propia experiencia, puede obtener conocimiento de estas experiencias para implementarlas en los movimientos futuros. Esta es probablemente la diferencia más grande e imperativa entre los conceptos de refuerzo y aprendizaje supervisado. En estos dos tipos de aprendizaje, hay un cierto tipo de mapeo entre la salida y la entrada. Pero en el concepto de aprendizaje reforzado, existe una función de recompensa ejemplar, a diferencia del aprendizaje supervisado, que le permite al sistema conocer su progreso en el camino correcto.
Poner orden es en la mejora de las competencias en TIC de la enseñanza mediante la adaptación a los requerimientos de cada disciplina dentro de la sociedad de la información con diferentes interfaces de usuario. Es necesario el uso de los conceptos de la responsable de la adquisición de habilidades específicas de la disciplina sector de las TIC, conocimiento fijación, de desarrollo personal.
El aprendizaje de refuerzo básicamente tiene una estructura de mapeo que guía a la máquina desde la entrada hasta la salida. Sin embargo, el aprendizaje no supervisado no tiene tales características presentes en él. En el aprendizaje no supervisado, la máquina se centra en la tarea subyacente de ubicar los patrones en lugar del mapeo para avanzar hacia la meta final, por eso en este paso deberemos obviarlo, en el sentido posterior de su ejecución, es decir, utilizaremos sus patrones durante el proceso, pero después del mismo deberemos derivarlo hacia el aprendizaje SUPERVISADO, ya que es la única manera de llegar al PERSONALIZED LEARNING, por medio de una aplicación.
Por ejemplo, si la tarea de la máquina es sugerir una buena actualización de noticias a un usuario, un algoritmo de aprendizaje de refuerzo buscará recibir retroalimentación regular del usuario en cuestión, y luego a través de la retroalimentación construirá un gráfico de conocimiento confiable de todas las noticias. Artículos relacionados que le gusten a la persona. Por el contrario, un algoritmo de aprendizaje no supervisado intentará ver muchos otros artículos que la persona ha leído, similar a este, y sugerir algo que coincida con las preferencias del usuario.
Los reinos en el aprendizaje automático son infinitos. Puede visitar mi canal de YouTube para conocer más sobre el mundo de la IA y cómo el futuro será dictado por el uso de datos en las máquinas.
La tecnología abre nuevas formas radicales de la educación; romper barreras entre disciplinas impulsa nuevos campos creativos de la investigación y la invención; y poniendo el emprendimiento social en el centro de la misión de una universidad asegura pensadores brillantes jóvenes pueden llegar a ser nuestros más poderosos solucionadores de problemas.
A través de una colaboración continua, el intercambio de ideas y una buena dosis de coraje, estamos en el camino correcto para asegurar un cambio duradero en nuestra sociedad y en nuestra educación. Estoy emocionado de ver las ideas como éstas crecen y se transforman el futuro de la educación..
Para todo ello proponemos preguntas como:
-Cuáles son las dimensiones interculturales clave a considerar en equipos distribuidos?
-¿Cómo dimensiones culturales y sus diferencias se refieren a las preferencias de los canales de comunicación?
-¿Cómo afecta el uso de estas herramientas de una cultura a otra y por qué?
-¿Cuáles son los problemas típicos que surgen cuando los miembros de diferentes culturas tienen que trabajar juntos?
-¿Qué tipo de herramientas y canales de comunicación deben estar disponibles para colaborar en línea?
Con ello vamos a maximizar el rendimiento de la máquina de una manera que le ayuda a crecer. Aquí se requiere una retroalimentación simple que informe a la máquina sobre su progreso para ayudar a la máquina a conocer su comportamiento.
El aprendizaje por refuerzo no es simple, y es abordado por una gran cantidad de algoritmos diferentes, de hecho un agente decide la mejor acción en función del estado actual de los resultados.
El crecimiento en el aprendizaje por refuerzo ha llevado a la producción de una amplia variedad de algoritmos que ayudan a las máquinas a conocer el resultado de lo que están haciendo. Ya que tenemos una comprensión básica del Aprendizaje de Refuerzo a estas alturas, podemos comprender mejor formando un análisis comparativo entre el Aprendizaje de Refuerzo y los conceptos de Aprendizaje Supervisado y No Supervisado.
Las tecnologías de la información digital están transformando la manera en que trabajamos, aprendemos, y nos comunicamos. Dentro de esta revolución digital son los nuevos enfoques de aprendizaje que transforman los modelos jerárquicos, basado en la industria de la enseñanza y el aprendizaje. …
Consejos prácticos, ejemplos de la vida real, estudios de casos, y la oferta de recursos útiles perspectivas en profundidad sobre la estructuración y el fomento del aprendizaje socialmente atractivo en un entorno online….serán los que nos harán cambiar de una vez, que nos permitirán arriesgarnos y saber “estar” y vivir dentro de la incertidumbre, de una manera mucho más creativa que hasta ahora…
Sólo un ser humano realmente puede personalizar todo lo que él o ella lo hace. Es la era de la personalización, pero eso sólo significa ayudar a cada uno de nosotros para pasar menos tiempo en los detalles y más tiempo en las actividades humanas importantes, como la imaginación, la creatividad, el descubrimiento, la integración, la intuición, ..
La personalización por las tecnologías digitales sólo libera los seres humanos para personalizar mejor nuestra vida (es decir, encontrar nuestras propias maneras), lo demás deben hacerlo las tecnologías y e aqui mi insistencia en conseguir un ALGORITMO, el cual pueda facilitar la recepcion de DATOS, pasarlos por un proceso de ANALISIS Y CRITICA, lo que los transformara en APRENDIZAJES. Si todo el proceso esta evaluado, necesitaremos el algoritmo para que nos realice la retroalimentación. Lo cual hara que todo nuestro proceso de aprendizaje este ayudado por este proceso tecnológico.
El mismo Pierson dice “Las evaluaciones se incrustan en las actividades de contenido y aprendizaje por lo que la instrucción y el aprendizaje no tiene que ser interrumpidos para determinar las áreas de progreso y desafío continuo. Mientras tanto, los algoritmos y las progresiones de aprendizaje integrados en el sistema van a ajustar en respuesta a las actividades de aprendizaje relacionadas del estudiante para permanecer en sintonía con sus ecosistemas de aprendizaje. Esta información también se proporciona al educador con opciones y recursos adicionales en tiempo real ya que el educador puede utilizarlo para apoyar al estudiante y su aprendizaje”
Como esta nueva tecnología comienza a tomar forma el diseño de otra sociedad ya que SUS MIMBRES son completamente nuevos a no como herramientas, metodologías…(innovaciones), sino un cambio “radical” en la concepción de la misma sociedad.
Algunos pensaran que en parte estamos en el APRENDIZAJE ADAPTATIVO, ya que nos basamos en los DATOS, pues no, lo hacemos así como una IDEA COMPLETAMENTE NUEVA, es decir, utilizamos DATOS, si, pero dentro del proceso personalizado de aprendizaje, por lo tanto se trata de algo completamente diferente.
Estos algoritmos de personalización (Rauch, Andrelczyk y Kusiak, 2007), recopilar información del usuario y analizan los datos para que pueda ser transmitida al usuario en momentos específicos (Venugopal, Srinivasa y Patnaik, 2009). Por ejemplo, cuando estoy terminado de ver un video en YouTube o una película en digital y he aquí que presenté con una lista de recomendaciones sobre los géneros que acabo consumidas. Esta idea funciona de forma similar con algoritmos de personalización que sería capaz de recomendar cursos o avenidas de aprendizaje basado en el conocimiento previo alumnos o cursos completados.
Es nuestra responsabilidad en esta sociedad:….
-Aplicar las técnicas de minería de datos, aprendizaje automático y reconocimiento de patrones para los conjuntos de datos estructurados y no estructurados.
-Diseño, desarrollo y prueba de algoritmos de aprendizaje y modelos de datos sobre el comportamiento humano para construir instrumentos de evaluación cognitiva
-Construir algoritmos personalizados para un motor de recomendación vía de desarrollo
-Los modelos de diseño para el desarrollo de aplicaciones nuevo juego
-Contribuir a la mejora de nuestros algoritmos.
También nos podemos hacer una serie de preguntas que no vamos a obviar….y que nos ayudaran a entender mejor el por qué de las cosas:…
¿El aprendizaje PERSONALIZADO tiene suficiente mejoría en el aprendizaje del aprendiz para justificar los costos de un sistema de aprendizaje más complejo?
¿Cómo podemos aprovechar algoritmos de aprendizaje automático “big data” y otros.. para la construcción de sistemas de aprendizaje personalizadas más eficientes y rentables?
¿Cómo pueden las ideas y resultados de la investigación de las ciencias cognitivas, utilizarlos para mejorar la eficacia de los sistemas de aprendizaje personalizados?.
En los últimos tiempos se están dando corrientes referentes al Big data y a los Algoritmos (Inteligencia Artificial), los que predicen que significaran la “visualización” de una época con rayos y truenos, que nos tendra vigilados permanentemente ” Un artículo del periodista holandés Dimitri Tokmetzis demostró el año pasado hasta qué punto esto puede ir en los datos de montaje de retratos compuestos de lo que somos. Google sabe lo que busca y puede inferir no sólo qué tipo de noticias que lees en un domingo por la mañana y qué tipo de películas prefieres un viernes, qué tipo de porno que probablemente nos gustaría mirar y dejarnos boquiabiertos en la noche del sábado , lo que ha hecho que los bares y restaurantes cierren”….
La propuesta de Bentham para una Máquina total de la visibilidad puede ser menos significativa a la tesis de los universos de datos emergentes que sus contribuciones a la moral del utilitarismo y su supuesto de que se puede medir nuestro bienestar.
El panóptico es un tipo de arquitectura carcelaria ideada por el filósofo utilitarista Jeremy Bentham hacia fines del siglo XVIII. El objetivo de la estructura panóptica es permitir a su guardián, guarnecido en una torre central, observar a todos los prisioneros, recluidos en celdas individuales alrededor de la torre, sin que estos puedan saber si son observados”.
El efecto más importante del panóptico es inducir en el detenido un estado consciente y permanente de visibilidad que garantiza el funcionamiento automático del poder, sin que ese poder se esté ejerciendo de manera efectiva en cada momento, puesto que el prisionero no puede saber cuándo se le vigila y cuándo no”….
ste dispositivo debía crear así un «sentimiento de omnisciencia invisible» sobre los detenidos. El filósofo e historiador Michel Foucault, en su obra Vigilar y castigar (1975), estudió el modelo abstracto de una sociedad disciplinaria, inaugurando una larga serie de estudios sobre el dispositivo panóptico. «La moral reformada, la salud preservada, la industria vigorizada, la instrucción difundida, los cargos públicos disminuidos, la economía fortificada, todo gracias una simple idea arquitectónica.» — Jeremy Bentham, Le Panoptique, 1780.
Estamos hoy en la clase difusa del pensamiento calculador y comparaciones cuantitativas insta a que el utilitarismo, tal razonamiento no se basa en el trabajo de visibilidad a hacer. Más bien, eso depende de algoritmos de análisis, qui a su vez depende de la presa de los algoritmos silenciosos –los que convierten en silencio nuestro comportamiento en una avalancha de datos. (son la metáfora de los presos alrededor que se pusieron alrededor de una torre de vigilancia para ser visualizados, hasta que estos alcanzaron la manera de evitarlo( estos eran los algoritmos)….
Este precio informativo se compone de DATOS ESTANDARIZADOS a través del que hemos llegado a definir nosotros mismos: transcripciones escolares, registros de salud, cuentas de crédito, títulos de propiedad, identidades legales. Hoy en día, tesis arraigada tipo de individualidad datos están siendo blanco amplió para abarcar más y más de lo que podemos ser: (En educación seria el PERSONALIZED LEARNING, que nosotros mismos abogamos y además instauramos en algoritmos personalizados, nunca creadores de patrones)..
La transformación es el cambio de una o muchas variables en el estudio.
Se transforman variables, por ejemplo, al remplazar los valores originales por logaritmos (transformación logarítmica). Frecuentemente los datos que son obtenidos no se ajustan a una distribución normal, por lo cual es inapropiado el ejecutar pruebas paramétricas
Muchas variables no se comportan de forma lineal o aritmética, por ejemplo las abundancias siguen un patrón exponencial.
En la educación básica se promueve que el sistema decimal es el único “natural”
Nunca vemos los algoritmos que hacen su trabajo, incluso a medida que nos afectan. Ellos producen en sus sistemas de cifrado, todo invisible, enterrado en cajas negras componer silencio sinfonías de ceros y unos….
Pierre Levy, el pensador de TUNEZ, propone una forma de procesar la información «codificándola» en algoritmos. Los humanos tenemos una habilidad muy especial, que es la de manipular símbolos. Y a lo largo de nuestra historia, cada mejora en esa habilidad ha producido cambios muy significativos a nivel económico, social, político, religioso, epistemológico, científico y educativo. Esos cambios, que trazan una evolución cultural, van desde los rituales y narrativas primigenios, la invención de la escritura, la creación de alfabetos y sistemas numéricos consensuados y permanentes, la fabricación de un artefacto tecnológico como la imprenta hasta arribar a la automatización de la reproducción en la difusión de símbolos.
Todos esos pasos aumentaron la posibilidad de almacenamiento de nuestra memoria, la expandieron, incrementaron la inteligencia colectiva y subieron un nivel en la escala evolutiva cultural.
En ese sentido, la propuesta de Lévy se aleja de la inteligencia artificial. La suya es una perspectiva completamente distinta: para él no se trata de crear máquinas inteligentes o más inteligentes que los humanos, sino de hacer a los humanos más inteligentes. Cada nivel de complejidad implica un tipo de conocimiento emergente nuevo y más poderoso, en el que todos los procesos cognitivos están aumentados. El último paso, es decir, aquel hacia el cual tendemos, sería el conocimiento algorítmico.
Y esa propuesta es la que hacemos nosotros (JUAN DOMINGO FARNOS https://juandomingofarnos.wordpress.com/…/algoritmos…/
INCLUSO DENTRO DE UN PROCESO transversal y multidisciplinar, para lograr nos lo eso, sino una autonomía en los aprendizajes y una personalizacion, como nunca hasta ahora se ha producido (POR TANTO TOTALMENTE ORIGINAL, apoyada en todo lo que les escribo, más las distintas potencialidades que tenemos de aprendizaje que tenemos las personas en nuestro cerebro y que les visualizo.
No podemos confundir la aplicación de los algoritmos en el aprendizaje personalizado (personalized learning), algunos lo llaman educación personalizada, aunque realmente está muy lejos uno de la otra, como realizar clases particulares, tal como hacen algunas escuelas de Nueva York, “utiliza el análisis de aprendizaje para desarrollar en las matemáticas personalizadas programas de aprendizaje. La Escuela con algoritmos de aprendizaje realiza evaluaciones cotidianas de estilos de aprendizaje y matemáticas de los estudiantes, y lo hace para producir un aprendizaje “lista de reproducción” personalizado para cada alumno. Esta lista se compone de clases particulares de matemáticas, que se ponen en el orden en que el algoritmo determina que es óptimo para el desarrollo de las habilidades matemáticas de los estudiantes. Ciertamente, Escuela de uno se apresura a señalar que este está destinado a complementar, no sustituir, la experiencia de un maestro individual”..
La personalización por las tecnologías digitales sólo libera los seres humanos para personalizar mejor nuestra vida (es decir, encontrar nuestras propias maneras), lo demás deben hacerlo las tecnologías y e aquí mi insistencia en conseguir un ALGORITMO, el cual pueda facilitar la recepción de DATOS, pasarlos por un proceso de ANALISIS Y CRITICA, lo que los transformará en APRENDIZAJES. Si todo el proceso esta evaluado, necesitaremos el algoritmo para que nos realice la retroalimentación. Lo cual hara que todo nuestro proceso de aprendizaje este ayudado por este proceso tecnológico, pero siempre seremos nosotros quienes elijamos en última instancia el camino que vamos a seguir, frente a las múltiples propuestas en “beta” que nos presentará la tecnología.
Pronto el registro y análisis de datos semánticos podrá convertirse en un nuevo lenguaje común para las ciencias humanas y contribuir a su renovación y el desarrollo futuro.
Todo el mundo será capaz de clasificar los datos como quieran. Cualquier disciplina, ninguna cultura, ninguna teoría será capaz de clasificar los datos a su manera, para permitir la diversidad, utilizando un único metalenguaje, para garantizar la interoperabilidad. (EXCELENCIA PERSONALIZADA AUTOMATIZADA,) por medio de una mezcla de inteligencia artificial y algorítmica.
Si partimos de la idea de que la REALIDAD es múltiple, podemos entender por qué aprender en la diversidad no tiene porque llevarnos a un punto común-….esta premisa es fundamental para entender el pensamiento crítico en los aprendizajes y sin la cuál sería imposible llevar a cabo aprendizajes basados en la diversidad-INCLUSIVIDAD (EXCELENCIA)…
Todo el mundo será capaz de clasificar los datos como quieran. Cualquier disciplina, ninguna cultura, ninguna teoría será capaz de clasificar los datos a su manera, para permitir la diversidad, utilizando un único metalenguaje, para garantizar la interoperabilidad. (EXCELENCIA PERSONALIZADA AUTOMATIZADA, por medio de una mezcla de inteligencia artificial y algorítmica.
“Vamos ya a aprender durante toda nuestra vida y en cualquier momento, el qué, cuándo, cómo y dónde (eligiendo con quién), ya han dejado de ser, una obligación para pasar a seer algo usual en nuestra vida, las TIC, Internet, la Inteligencia Artificial, “han dinamitado” todo ese planteamiento que no sabíamos ni podíamos superar, ahora el estaticismo de aprender de manera controlada, uniforme, el “ocupar un espacio y un tiempo”, han dejado ya de existir, por lo cual, vivimos aprendiendo, aprendemos en cada momento de nuestra vida, por eso, cualquier planteamiento que hagamos en este impás, debe acomodarse a esta nueva manera de entender la vida que ya está aquí, pero estamos “suscribiendo” las maneras de llegar a ello”.
juandon
BIBLIOGRAFÍA:
- Yann LeCun: Yann LeCun es uno de los pioneros en el campo del aprendizaje profundo y es conocido por su trabajo en redes neuronales convolucionales (CNN). Ha trabajado en instituciones como la Universidad de Nueva York (NYU) y Facebook AI Research (FAIR).
- Geoffrey Hinton: Geoffrey Hinton es otro pionero en el campo del aprendizaje profundo y redes neuronales. Trabajó en la Universidad de Toronto y Google, y ha hecho contribuciones significativas a la investigación en redes neuronales profundas.
- Andrew Ng: Andrew Ng es un experto en aprendizaje automático y co-fundador de Coursera, una plataforma de educación en línea. Ha enseñado cursos populares de aprendizaje automático en línea y es profesor en la Universidad de Stanford.
- Fei-Fei Li: Fei-Fei Li es una científica de datos e investigadora en inteligencia artificial. Trabajó en Stanford y Google y es conocida por su trabajo en visión por computadora y educación en IA.
Universidades Destacadas:
- Universidad de Stanford: Stanford es conocida por su departamento de Ciencias de la Computación y es un importante centro de investigación en inteligencia artificial y aprendizaje automático.
- Universidad de Carnegie Mellon: CMU es reconocida por su enfoque en la inteligencia artificial y la robótica, y tiene un destacado departamento de Informática.
- Universidad de Oxford: La Universidad de Oxford es líder en investigación en IA, con el Oxford Robotics Institute y otros centros de investigación destacados.
- MIT (Instituto de Tecnología de Massachusetts): MIT es conocido por su trabajo en IA y aprendizaje automático a través del MIT Computer Science and Artificial Intelligence Laboratory (CSAIL).
- Universidad de California, Berkeley: UC Berkeley es otro centro de investigación importante en IA, con investigadores influyentes en el campo.
- Universidad de Toronto: La Universidad de Toronto ha sido líder en el desarrollo de redes neuronales profundas y tiene un fuerte enfoque en la investigación en IA.
- Universidad de Nueva York (NYU): NYU, en particular a través del NYU Center for Data Science, ha estado involucrada en investigación en aprendizaje automático y ciencia de datos.
- Universidad de Cambridge: La Universidad de Cambridge también tiene una presencia destacada en investigación en IA y aprendizaje automático.
Este es nuestro campo de trabajo de los ALGORITMOS CON EL PERSONALIZED LEARNING https://juandomingofarnos.wordpress.com/tag/algoritmos/ Juan Domingo Farnós Miró
Vagale, Vija “ERSONALIZATION OPPORTUNITIES IN THE MOODLESYSTEM” http://www.academia.edu/3275982/PERSONALIZATION_OPPORTUNITIES_IN_THE_MOODLE_SYSTEM
B. Mobasher, “Minería de Datos para la personalización,” La Web Adaptativo: Métodos y Estrategias de Web Personalización, P. Brusilovsky, A. Kobsa, y W. Nejdl, eds., Pp. 1–46, Springer, 2007.
AI Schein, A. Popescul, y LH Ungar, “Métodos y métricas para arranque en frío Recomendaciones”, Proc. 25 de Ann. Int’l ACM SIGIR Conf. Investigación y Desarrollo en Recuperación de Información, pp. 253–260, 2002.
S. McNee, J. Riedl, y JA Konstan, “Siendo precisa no es suficiente: Cómo métricas de precisión han herido de recomendación Systems,” Proc. ACM SIGCHI resúmenes sobre Factores Humanos en Sistemas Informáticos (CHI EA ’06), pp Extended. 1097–1101, 2006.
http://www.pearson.com.ar/pte.php
http://thenewinquiry.com/…/the-algorithm-and-the…/ The Algorithm and the Watchtower
By Colin Koopman
Vagale, Vija “ERSONALIZATION OPPORTUNITIES IN THE MOODLESYSTEM” http://www.academia.edu/…/PERSONALIZATION_OPPORTUNITIES…
- Michael Fullan: ha trabajado en el desarrollo de nuevas pedagogías para el aprendizaje profundo.
- Ron Ritchhart: ha investigado sobre rutinas de pensamiento para una comprensión profunda.
- Alejandra Pereyras: ha escrito sobre el aprendizaje profundo y su aplicación en la educación.
- Juan Domingo Farnós: ha trabajado en el uso de tecnologías disruptivas para transformar la educación y fomentar el aprendizaje personalizado y la colaboración entre estudiantes.
- Ken Bain: es autor del best seller «Lo que hacen los mejores profesores universitarios».
Universidades:
- Universidad de Harvard: ha realizado investigaciones sobre el aprendizaje profundo y las rutinas de pensamiento.
- Universidad Nacional de Colombia: ha trabajado en el desarrollo de algoritmos de aprendizaje profundo para el procesamiento de imágenes y el reconocimiento de patrones.
- Universidad de Los Andes: ha investigado sobre el aprendizaje profundo y su aplicación en la educación.
- Universidad de Chile: ha trabajado en el desarrollo de nuevas pedagogías para el aprendizaje profundo.
- Universidad de la República: ha investigado sobre el aprendizaje profundo y su aplicación en la educación.
Aquí hay algunos trabajos de investigación recientes sobre el aprendizaje profundo en las universidades:
- «Aprendizaje profundo y memes en ciencias básicas» de la Universidad de Concepción: Este estudio investiga el uso de memes en la enseñanza de ciencias básicas y cómo el aprendizaje profundo puede mejorar la comprensión de los estudiantes
- «Aprendizaje profundo en la formación docente: experiencia con estudiantes de Enseñanza de la Educación de la Universidad de Costa Rica» de la Universidad de Costa Rica: Este estudio explora cómo el aprendizaje profundo puede mejorar la formación docente y la enseñanza en el aula.
- «El aprendizaje profundo como herramienta para cambio en la visión de aprendizaje de una cultura escolar» de la Universidad Nacional de Colombia: Este estudio investiga cómo el aprendizaje profundo puede cambiar la visión de aprendizaje de una cultura escolar y mejorar la calidad de la educación
- «La exploración en el desarrollo del aprendizaje profundo» de la Universidad de Los Andes: Este estudio explora cómo la exploración puede mejorar el aprendizaje profundo y cómo se puede aplicar en la educación
- «Aprendizaje profundo a través de la resolución de problemas en estudiantes de noveno grado en la institución educativa San Francisco de Asís» de la Universidad Tecnológica de Pereira: Este estudio investiga cómo la resolución de problemas puede mejorar el aprendizaje profundo en estudiantes de noveno grado






Deja un comentario